Comment contourner le besoin de grands volumes de données de référence dans les modèles d’apprentissage automatique ?
La mise en œuvre de chaînes de cartographie automatique (occupation des sols, variables bio-physiques) reposant sur des méthodes d’apprentissage nécessite de grandes quantités de données de référence (vérités terrain, annotations par photo-interprétation) et des modèles de machine learning avec beaucoup de paramètres et donc gourmands en ressources de calcul.
Une façon de contourner ces difficultés est d’entraîner des modèles qui ne sont pas spécifiques à une tâche de cartographie particulière et qui fournissent des représentations des données qui concentrent un maximum d’information. Ce type de modèle peut être entraîné de façon non supervisée en utilisant les grandes masses de données d’archive disponibles. Avec ces représentations, des modèles légers spécifiques à une tâche particulière peuvent être entraînés à partir de petites quantités de données de référence.
Iris Dumeur, au cours de sa thèse au CESBIO, a proposé un modèle pour construire des représentations de séries temporelles d’images (Sentinel-2 ici, mais d’autres données similaires pourraient être utilisées). L’architecture proposée par Iris, appelée U-BARN, combine l’encodage spatio-spectral (Unet) et l’encodage temporel (Transformer) de façon originale. U-BARN permet de traiter des séries de longueur variable et échantillonnées de façon irrégulière. Des masques de nuages sont utilisés lors de l’entraînement, mais ils ne sont pas nécessaires lors de l’inférence.
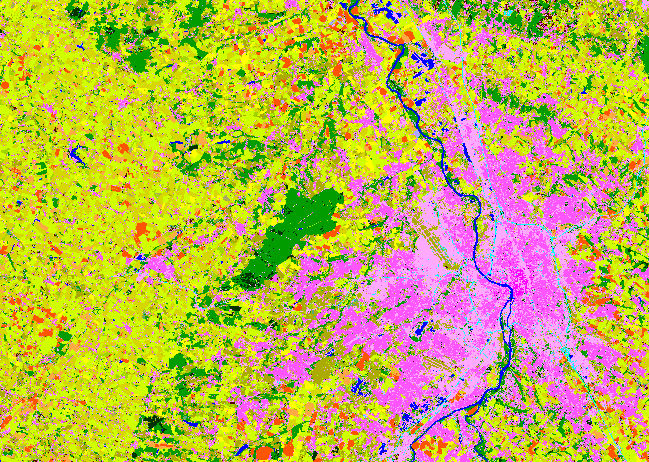
Le modèle a été appliqué à deux tâches : classification de cultures et occupation des sols générique. Dans les 2 cas, les résultats sont équivalents ou meilleurs que ceux des modèles de l’état de l’art, mais surtout U-BARN a des performances supérieures aux autres approches dans les cas avec peu de données de référence.
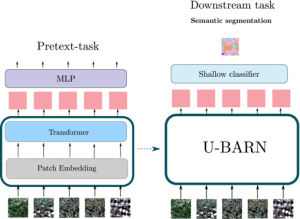
Schéma de la méthode développée : un modèle générique de représentation (à gauche) est pré-entrainé au moyen d’une tâche prétexte pour laquelle beaucoup de données sont disponibles (Images Sentinel-2), puis appliqué à la tâche spécifique (à droite) au moyen des quelques données de référence disponibles.

