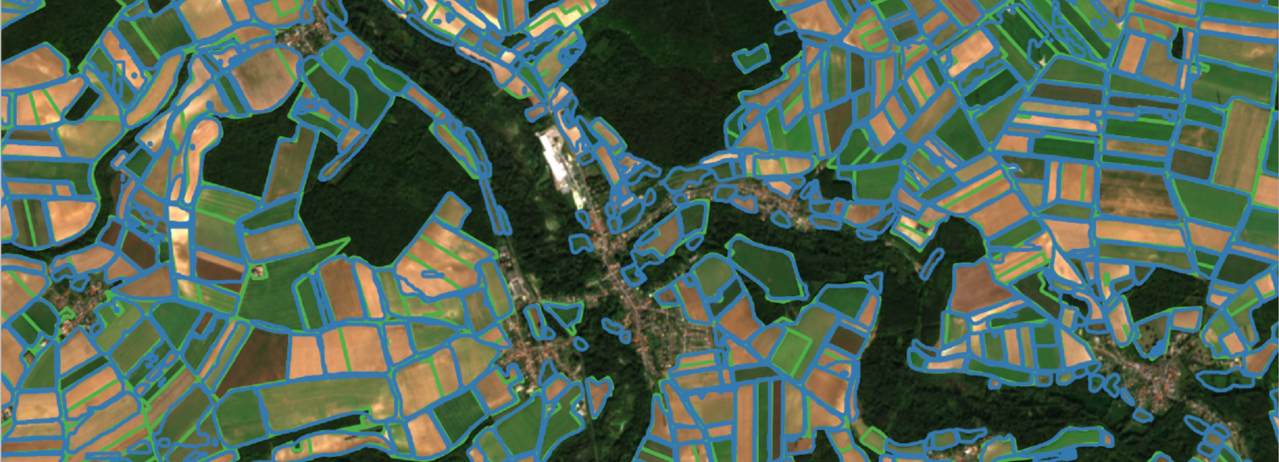
Le Mask R-CNN pour la délinéation de parcelles : retour d’expérience
Les techniques de l’état de l’art en Deep Learning permettent-elles une délinéation individuelle de chaque parcelle de culture, comme le laisse penser cet article récent ? C’est ce que nous avons cherché à savoir au cours d’un stage au CESBIO en cherchant à qualifier l’architecture Mask R-CNN pour cette tâche. Nous vous livrons ici les principaux enseignements.
Le Mask R-CNN en théorie
En bref, le Mask R-CNN est une architecture qui fonctionne en trois grandes parties. On a tout d’abord un réseau convolutif appelé backbone qui extrait des primitives à partir de notre image de départ. À partir de ces primitives, une seconde partie (le Region Proposal Network ou RPN) va proposer et affiner un certain nombre de régions d’intérêts (sous la forme de boîtes englobantes rectangulaires) susceptibles de contenir une parcelle. Enfin, la dernière partie va récupérer les meilleures propositions, les affiner de nouveau, et produire un masque de segmentation propre à chacune d’entre elles.
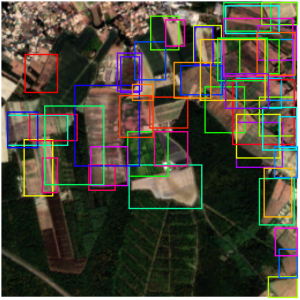
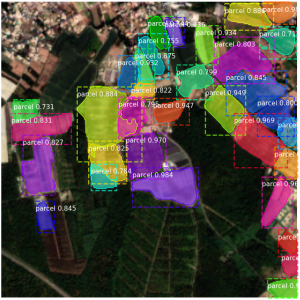
À gauche les propositions conservées par le RPN, à droite les détections finales du Mask R-CNN avec leurs masques de segmentation.
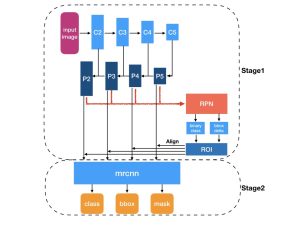
Un schéma récapitulatif du réseau se trouve ci-dessous, il provient ce court article, qui peut être un bon point d’entrée si vous souhaitez en savoir plus. Il est à noter qu’au total, ce réseau possède une centaine de couches de convolution – ce qui rend plus difficile sa manipulation, car il est plus difficile d’interpréter les résultats obtenus.
Le Mask R-CNN en pratique
Afin d’entraîner ce réseau, nous avons utilisé les données du Registre Parcellaire Graphique (RPG) distribué chaque année par l’IGN. Cette base de donnée étant lacunaire, nous y avons ajouté un complément produit par l’Observatoire du Développement Rural de l’INRAE. Afin de simplifier notre problème autant que possible, nous n’avons défini qu’une seule et unique classe, laissant ainsi de côté les types de culture fournies dans ces bases de données.
En ce qui concerne les données d’entrée, nous avons utilisé des images Sentinel-2 de niveau 2A fournies par Theia et plus exactement les 4 bandes spectrales à 10m de résolution (rouge, vert, bleu et proche infrarouge). Nous avons sélectionné 7 tuiles au dessus du territoire métropolitain, et choisi 4 dates différentes en 2018 pour chacune d’entre elle, durant les périodes de culture. Nous disposons aussi d’images super-résolues (à 5m plutôt que 10), qui sont produites grâce à un travail précédant au CESBIO (utilisant un Cascading Residual Network). Ces images permettent de gagner en netteté, par rapport aux bandes Sentinel-2 à 10m, aussi nous pensions également gagner en précision sur les contours prédits par nos modèles.
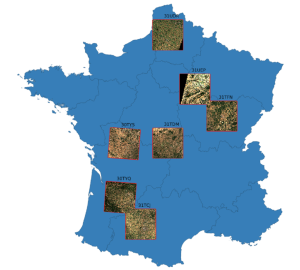
Tuiles sélectionnées (31UDR et 31UEP sont nos tuiles de test, les autres nos tuiles d’entraînement/validation)
Le Mask R-CNN ayant déjà été expérimenté dans la littérature pour cette même tâche de segmentation par instance des parcelles, nous avons tenté de reproduire le travail de ces auteurs. Bien que cette publication utilise une implémentation basée sur Tensorflow, nous avons d’abord cherché à reproduire ces résultats en utilisant l’implémentation fournie par le module Torchvision de Pytorch. Or nous n’avons jamais réussi à faire converger cette implémentation, et avons au passage noté de nombreuses différences entre ces deux implémentations. Les modèles pré-entraînés fournis l’ont été avec la base de données Image-Net pour Pytorch et COCO (plus dense en objets) pour Tensorflow, le pré-entraînement ne concerne que la partie backbone pour Pytorch mais couvre l’ensemble du réseau pour Tensorflow, et enfin l’implémentation elle même diffère dans l’ordre de certaines couches et le choix des primitives utilisées par les dernières étapes du réseau. Nous avons tenté d’isoler les éléments qui permettaient au réseau Tensorflow de converger, sans succès. Au temps pour la recherche reproductible !
Résultats
Après avoir écarté l’implémentation Pytorch, nous avons évalué plusieurs scénarii d’apprentissage, que nous pouvons séparer en trois groupes différents, décrits dans le tableau ci-dessous. Le premier groupe de scenarii contient les trois premiers entraînements, qui utilisent chacun une seule des quatre dates de nos tuiles d’entraînement, afin de tester la capacité de généralisation d’une date à un autre. On utilise toujours, comme trois premiers canaux, les bandes RVB, auxquels on ajoute soit le PIR, soit le NDVI. Les trois scenarii suivants tentent d’utiliser une approche multi-temporelle : soit on se contente d’utiliser l’ensemble de nos dates pour chaque tuile (aboutissant à un jeux de données quatre fois plus grand), soit on extrait le NDVI de chaque date avant de les empiler ; on utilise ainsi une pile multi-temporelle. Enfin, les 3 derniers entraînements utilisent des images super-résolues.
| Nom | Dates | Canaux | Résolution |
|---|---|---|---|
| T09NIR | Septembre | BVR – PIR | 10 m |
| T06NIR | Juin | BVR – PIR | 10 m |
| T09NDVI | Septembre | BVR – NDVI | 10 m |
| TADNIR | Toutes | BVR – PIR | 10 m |
| TADNDVI | Toutes | BVR – NDVI | 10 m |
| TMTNDVI | Toutes (empilées) | NDVI (dates 1 à 4) | 10 m |
| T09NIRSR | Septembre | BVR – PIR | 5 m |
| T09NDVISR | Septembre | BVR – NDVI | 5 m |
| T09NDVISRSA | Septembre | BVR – NDVI | 5 m |
Avec ces entraînements, on obtient quelques résultats intéressants qualitativement (à défaut d’être bons quantitativement). Lors d’une inférence, nous produisons un ensemble de polygones, chacun assorti d’un score de confiance. Sur ce score de confiance nous pouvons fixer un premier seuil, au dessous duquel les prédictions ne seront pas considérées.

Pour ensuite les associer à notre ensemble de polygones cibles, nous avons utilisé un critère géométrique illustré ci-contre. Ce critère estime si une cible (rectangle vert) et une prédiction (ellipse rouge) possèdent une intersection (en jaune) suffisante pour que leur correspondance soit jugée valide. En calculant deux ratios (jaune sur vert et jaune sur rouge), puis en prenant le minimum, on s’assure d’être le plus restrictif possible. La valeur obtenue est appelée RC, et on peut également fixer un seuil sur celui-ci afin d’être plus ou moins strict sur la qualité de nos prédictions. Une fois les associations entre les prédictions et les cibles effectuées, on peut alors calculer les métriques classiques de détection que sont la précision, le rappel et le F1-Score. La précision correspond au nombre de nos prédictions qui sont effectivement des cibles, le rappel correspond au nombre de cibles détectées, et le F1-Score est un compromis entre les deux premiers.
Sur l’ensemble de nos cas d’usage, ce sont les entraînements T09NDVISR et TMTNDVI qui ont fourni les meilleurs résultats, comme on peut le voir dans le tableau ci-dessous. Nous y avons utilisé des seuils assez restrictifs, à savoir 0.8 pour les deux valeurs (la confiance et le RC).
| Test | Précision | Rappel | F1-Score |
|---|---|---|---|
| T06NIR (sur juin) | 35.34 | 25.61 | 29.7 |
| T06NIR (sur septembre) | 31.51 | 21.45 | 25.52 |
| T09NIR (sur juin) | 30.08 | 20.8 | 24.6 |
| T09NIR (sur septembre) | 30.31 | 21.79 | 25.35 |
| T09NDVI (sur juin) | 31.03 | 21.43 | 25.35 |
| T09NDVI (sur septembre) | 29.79 | 21.21 | 24.78 |
| TADNIR | 34.51 | 25.11 | 29.07 |
| TADNDVI | 39.35 | 26.88 | 31.94 |
| TMTNDVI | 42.56 | 30.28 | 35.39 |
| T09NIRSR | 34.24 | 38.26 | 36.13 |
| T09NDVISR | 36.92 | 39.35 | 38.09 |
| T09NDVISRSA | 34.38 | 37.78 | 36.0 |
Afin de comparer nos performances à celles des auteurs de la publication mentionnée plus haut, nous avons choisi un seuil de RC à 0.5 et un seuil de confiance à 0.7. Les résultats sont montrés dans le tableau ci-dessous.
| Test | Précision | Rappel | F1-Score |
|---|---|---|---|
| T09NDVISR | 55.79 | 59.41 | 57.30 |
| TMTNDVI | 75.73 | 55.86 | 64.13 |
| OSO (sur 31UDR) | 45.89 | 22.54 | 30.23 |
| Auteurs | 68.7 | 48.5 | 56.2 |
Notre pile multi-temporelle de NDVI semble donc fournir des information pertinentes, et parvient à faire mieux que les résultats déclarés par les auteurs (sur leurs propres tuiles de test). La super résolution est quant à elle un peu en dessous en termes de métriques de détection, et au final on est très proche des résultats obtenus par les auteurs (on gagne sur le rappel mais on perd sur la précision). Toutefois, les bonnes prédictions fournies semblent être de meilleure qualité. En effet, les contours fournis (dont on peut voir un extrait ci-dessous, à deux échelles différentes) collent davantage aux parcelles de référence : l’entraînement à l’aide d’images super-résolues semble donc bien fournir des contours plus précis.
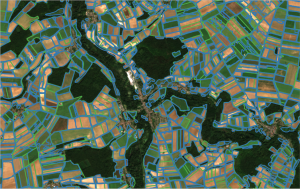

Parcelles cibles (en vert) et prédictions du modèle T09NDVISR (en bleu)
Pour finir, nous avons également soumis le produit OSO vectorisé à notre procédure d’appariement, afin de justifier la pertinence d’une approche de segmentation par instance. Nous avons fait ce test sur la tuile 31UDR, et on constate sans grande surprise que le rappel est très bas – puisque le produit OSO va notamment fusionner des parcelles de mêmes cultures qui sont côte-à-côte, on va donc avoir un grand nombre de cibles non détectées. Cela justifie ainsi l’intérêt d’utiliser une approche de segmentation par instance. Malgré cela, les résultats obtenus sont, à ce stade, bien loin d’être exploitables pour un utilisateur final. Il est à noter cependant que, à cause de notre critère d’appariement des prédictions aux cibles, il nous est impossible de détecter la fragmentation (le fait de détecter une cible en plusieurs prédictions) ou l’agglomération (le fait de détecter plusieurs cibles avec une seule prédiction). Pourtant, sur l’image, certaines fragmentations ou agglomérations pourraient sembler légitime, aussi nous sous-estimons nécessairement nos résultats.
Article réalisé dans le cadre d’un stage au CESBIO financé par le CNES.
Merci à Julien, Jordi et Olivier pour l’aide précieuse qu’ils m’ont apportée durant ce stage.

