
Estimation à la parcelle du rendement des grandes cultures sur la France métropolitaine avec des séries temporelles d’images Sentinel-2
L’estimation du rendement
La connaissance du rendement agricole, que ce soit en prévision (avant la fin de la saison) ou en rétrospective (après la récolte) a beaucoup d’intérêt applicatif. On peut par exemple devenir riche en spéculant sur les marchés, et on peut prévoir des crises alimentaires (et aussi devenir riche en spéculant sur les marchés). Il existe d’autres usages de cette information comme par exemple l’étude de l’impact du changement climatique sur les cultures ou l’effet de certaines pratiques agricoles.
En France, le Service de la statistique et de la prospective (SSP) du Ministère chargé de l’agriculture produit chaque année la statistique agricole annuelle (SAA) et les données associées sont publiées sur le site Agreste. Pour ce qui concerne le rendement agricole, des estimations départementales pour chaque culture sont disponibles après chaque campagne agricole.
Ces estimations sont le résultat d’enquêtes auprès des exploitants, combinées par des experts à d’autres sources d’informations. Il s’agit d’un travail long et complexe qui pourrait bénéficier de l’observation par télédétection satellitaire.
Au CESBIO, nous avons eu l’opportunité d’avoir accès à des données de rendement issues de l’enquête TERLAB (TERres LABourables) menée par le SSP chaque année pour la production de la SAA. Nous avons utilisé ces données pour évaluer la possibilité d’estimer le rendement à l’échelle de la parcelle agricole à partir d’imagerie de télédétection.
Nous avons obtenu des résultats intéressants que nous vous présentons dans ce billet. Le rapport complet de l’étude est disponible en ligne.
L’enquête TERLAB
Les données que nous avons reçu correspondent au recueil par enquête téléphonique auprès des exploitants en 2017. Pour chaque exploitation, on dispose du rendement (en quintaux par hectare) pour chaque culture. Ce rendement n’est pas spatialisé, c’est à dire que chaque exploitant peut avoir plusieurs parcelles de la même culture avec des rendements différents. En croisant ces informations avec le Registre parcellaire graphique (RPG) de l’année correspondante, on peut associer à chaque parcelle d’une même exploitation le rendement obtenu par enquête, mais il sera différent du vrai rendement de la parcelle.
C’est avec ce type de données que nous travaillé : la géométrie de 225.367 parcelles distribuées sur 70 départements, chacune contenant l’information de type de culture ainsi que le rendement de cette culture pour l’exploitation.
Avec ces données, nous avons construit des modèles d’estimation de rendement à partir d’images Sentinel-2.
L’approche algorithmique
Nous avons choisi de travailler par apprentissage statistique et construire ainsi un modèle de régression non-linéaire qui génère une estimation de rendement par parcelle à partir d’observations satellite acquises pendant la campagne agricole.
Pour chaque parcelle agricole, nous avons construit un ensemble de descripteurs phénologiques simples à partir des séries d’images Sentinel-2 (des statistiques par trimestre de différents indices de végétation, vous trouverez les détails dans le rapport). Nous avons ensuite utilisé un algorithme d’apprentissage pour relier ces descripteurs à la valeur de rendement correspondante.
On pourrait se demander si le fait d’apprendre sur des données «fausses» (souvenez-vous que nous ne connaissons pas le rendement des parcelles, mais celui de l’ensemble de l’exploitation) permet d’apprendre un modèle fiable. En fait, si on choisit correctement l’algorithme d’apprentissage, on peut réussir à lisser un peu ce bruit dans les données. On fait aussi l’hypothèse que le rendement est très corrélé au climat, au type de sol et aux pratiques agricoles et que ces facteurs sont plutôt homogènes au sein d’une exploitation. En plus, le grand nombre d’échantillons disponibles permettent d’être robuste aux échantillons fortement aberrants qui sont minoritaires.
Les résultats
Dans cette étude, nous avons comparé deux approches. D’un côté, nous avons testé la possibilité de calibrer des modèles spatialement localisés pouvant travailler sur différentes cultures. Cette approche a montré des limites. Nous nous sommes ensuite concentrés sur un modèle mono-culture (nous avons choisi le blé tendre d’hiver, BTH pour ceux qui parlent couramment le RPG), mais applicable à l’ensemble du territoire. Nous avons donc utilisé 95.550 parcelles de blé pour apprendre (2/3 des parcelles) et tester (le 1/3 restant) le modèle de régression.
La figure ci-dessous montre les résultats de la validation. Les erreurs mesurées sont de 9.72 q/ha en RMSE. La figure montre une bonne corrélation entre les données TERLAB et les estimations issues de la donnée satellite. Des écarts importants existent pour les faibles rendements (inférieurs à 40 q/ha) pour lesquels la régression surestime. Il s’agit cependant de très peu de parcelles par rapport à l’ensemble de la validation (3.4 % pour un rendement TERLAB inférieur à 40 q/h).
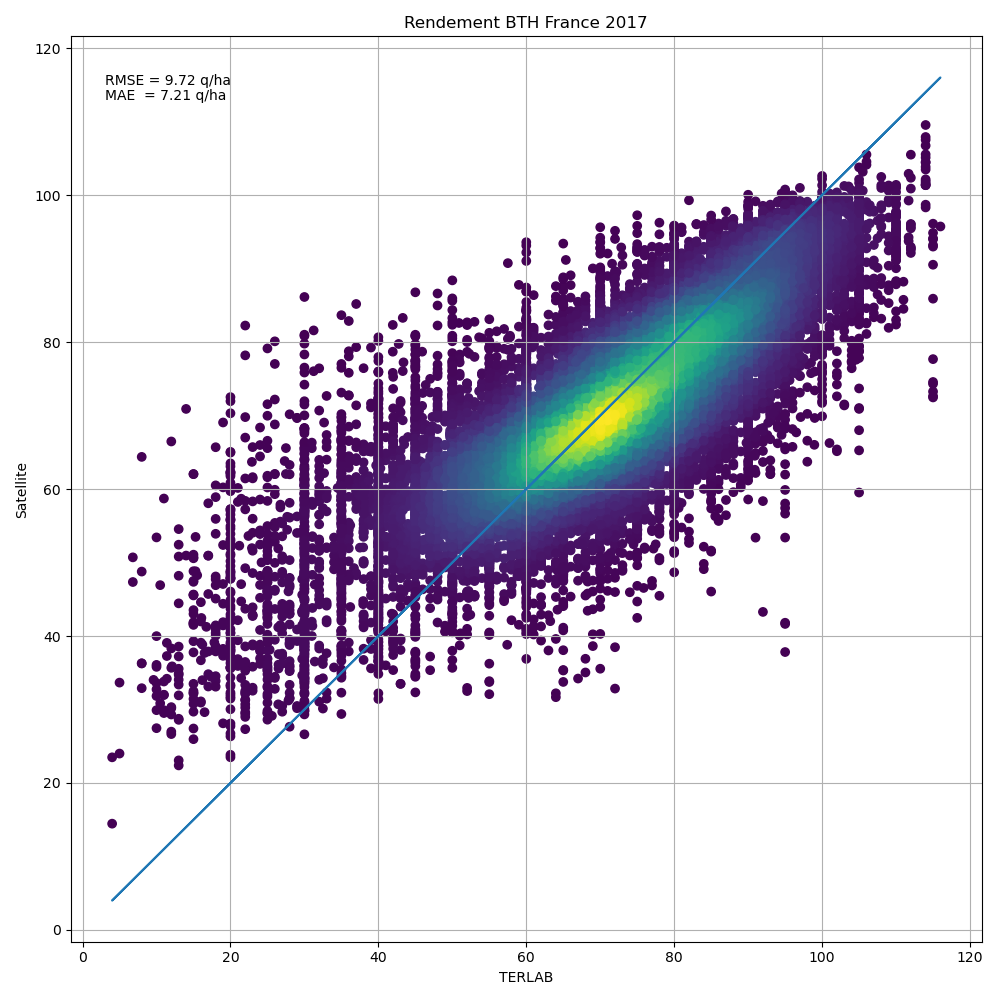
Cette validation reste limitée, car, comme expliqué plus haut, nous n’avons pas accès au vrai rendement de chaque parcelle. Nous avons donc décidé de comparer à la SAA et avons pris toutes les parcelles, leurs surfaces et les rendements estimés et nous avons calculé la production totale et le rendement moyen pour chaque département.
La figure suivante montre le résultat de la comparaison des estimations satellite et les données Agreste. La colonne de gauche présente les départements pour lesquels l’enquête TERLAB fournit des données pour le BTH, et la colonne de droite contient les départements pour lesquels aucune exploitation de BTH n’a été enquêtée.
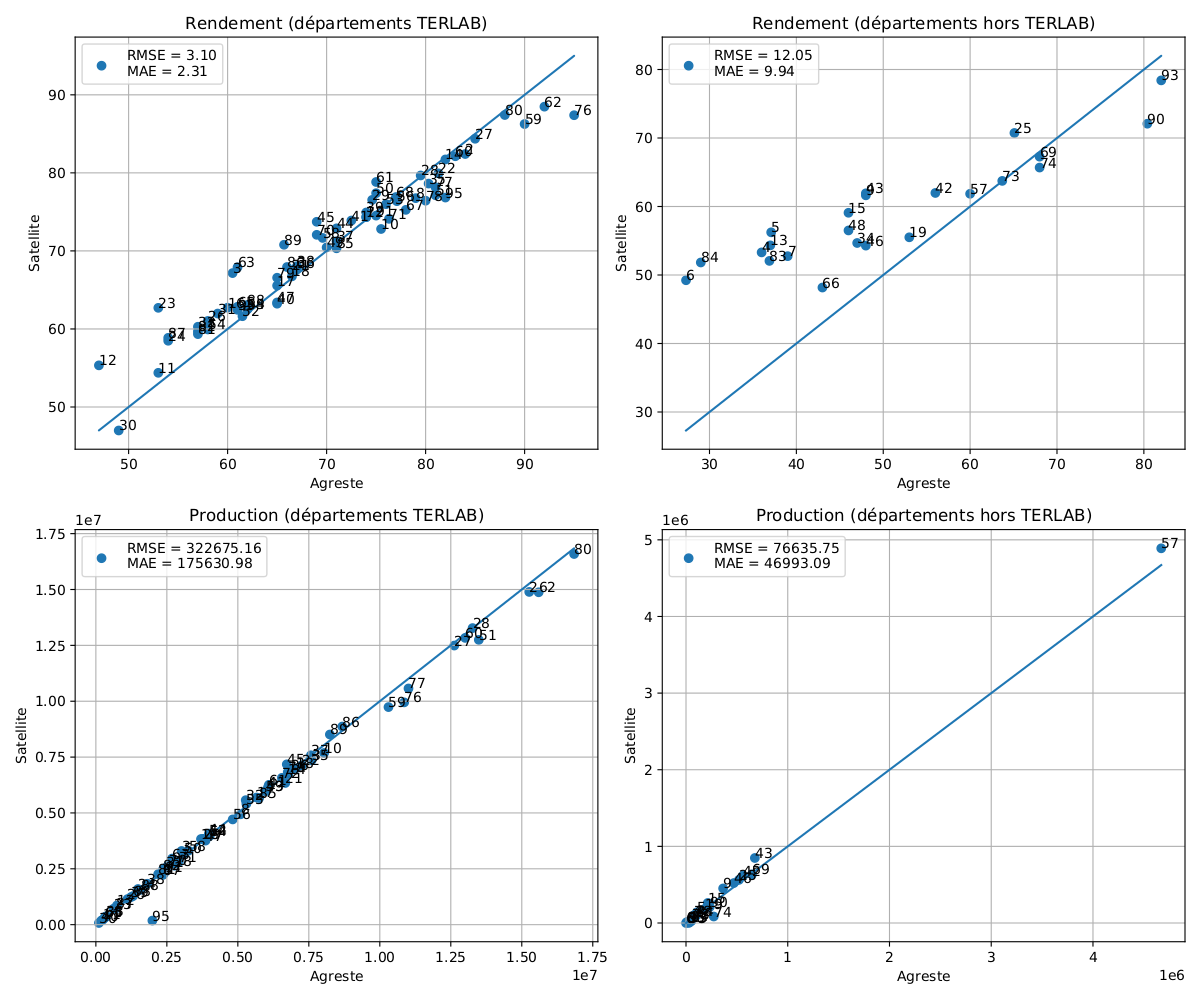
Nous observons que pour les départements TERLAB (colonne de gauche) les rendements sont proches de ceux de la SAA avec une légère sous-estimation pour les rendements élevés et une sur-estimation pour les faibles. C’est le même type de comportement observé pour le rendement à la parcelle. Les productions montrent la même sous-estimation pour les valeurs élevées, mais il ne semble pas y avoir de problème pour les faibles productions, ce qui est logique, car la pondération par les surfaces faibles fait chuter les erreurs.
La colonne de droite montre les résultats pour les départements sans donnée TERLAB pour le BTH. On constate une très bonne cohérence avec la SAA pour les productions. Il est intéressant de noter que la Moselle (57) constitue un cas atypique (production très élevée) dont l’estimation est très bonne. Le problème de la surestimation des faibles rendements est ici accentuée par le fait que beaucoup de départements non enquêtés ont de faibles rendements.
Conclusion
Cette étude a montré qu’il est possible d’estimer le rendement des grandes cultures à l’échelle de la parcelle à partir de séries d’images satellite optiques de type Sentinel-2.
Il reste encore du travail à faire, car il faudrait valider que d’autres cultures, comme le maïs ou le tournesol, peuvent être traités avec la même approche (nous avons des résultats partiaux qui vont dans le bon sens).
L’utilisation du satellite pourrait simplifier le travail d’enquête, car l’apprentissage des modèles peut être fait avec moins d’exploitations que celles utilisées actuellement. Il serait intéressant d’évaluer l’applicabilité du modèle appris sur des données d’une année aux images acquises sur l’année suivante, ce qui permettrait aussi de réduire la fréquence de l’enquête.
Enfin, l’application de l’approche au cours de saison, pourrait permettre d’avoir des prévisions de rendement, et donc de devenir riche en spéculant sur les marchés.

