Training deep neural networks for Satellite Image Time Series with no labeled data
The results presented in this blog are based on the published work : I.Dumeur, S.Valero, J.Inglada « Self-supervised spatio-temporal representation learning of Satellite Image Time Series » in IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, doi: 10.1109/JSTARS.2024.3358066.
In this paper, we describe a self-supervised learning method to train a deep neural network to extract meaningful spatio-temporal representation of Satellite Image Time Series (SITS). The code associated to this article is also available.
This work is part of the PhD conducted by Iris Dumeur and supervised by Silvia Valero and Jordi Inglada. In the last few years, the CESBIO team has developed machine learning models which exploit Satellite Image Time Series (SITS). For instance, the blog « End-to-end learning for land cover classification using irregular and unaligned satellite image time series » presents a novel classification method based on Stochastic Variational Gaussian Processes.
Context and Introduction
With the recent launch of numerous Earth observation satellites, such as Sentinel 2, a large amount of remote sensing data is available. For example, the Sentinel 2 mission acquires images with high spatial resolution (10 m), short temporal revisit (5 days), and wide coverage. These data can be exploited under the form of Satellite Image Time Series (SITS), which are 4-dimensional objects with temporal, spectral and spatial dimensions. In addition, SITS provide critical information for Earth monitoring tasks such as land use classification, agricultural management, climate change or disaster monitoring.
In addition, due to SITS specific acquisition conditions, SITS are irregular and have varying temporal sizes. Indeed, as detailed in this blog, the areas located on different orbital paths of the satellite have different acquisition dates and have a different revisit frequencies, causing respectively the unalignment and irregularity of SITS. Finally, Sentinel 2 SITS are affected by different meteorological conditions (clouds, haze, fog, or cloud shadow). Therefore, pixels within a SITS may be corrupted. Although validity masks are provided, incorrectly acquired pixels may be wrongly detected. In short, the development of models adapted to SITS requires to:
- Utilize the 4D temporal, spectral, and spatial information
- Deal with SITS irregularity and unalignement
- Ignore wrongly detected cloudy pixels
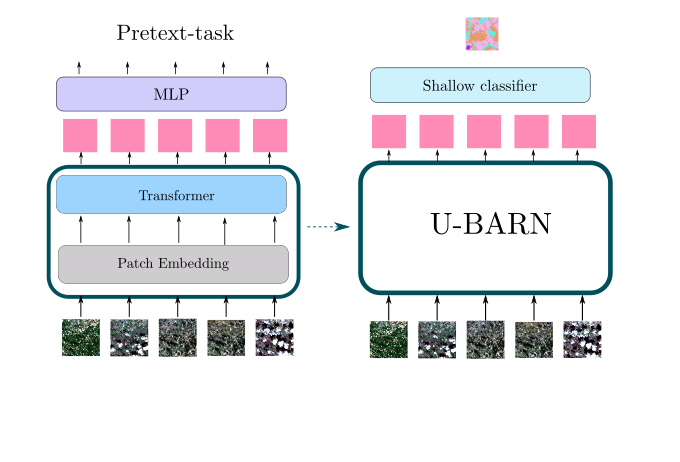
Moreover, while Deep Learning (DL) approaches have shown great performances in remote sensing tasks, these models are data greedy. In addition, building large labeled datasets is costly. Therefore, the training of DL models on large geographic and temporal scales is constrained by the scarcity of labels. Moreover, self-supervised learning has achieved amazing performance in other domains, such as image processing or natural language processing. Self-supervised learning is a branch of unsupervised learning in which the model is trained on a task generated by the data. In other words, the labels needed to supervise the task are generated thanks to the data. For example, in natural language processing, as illustrated in the following image, one common self-supervised pre-training task consists in training the model to recover masked words.

Self-supervised learning can be used to pre-train a model on a large unlabeled dataset. Notably, during pre-training, the model learns representations of the input data, which are then used by a decoder to perform the self-supervised task. In a second phase, these latent representations can be used for various supervised tasks, denoted downstream tasks. In this case, as illustrated in the following image, a downstream classifier is trained on top of the latent representations generated by the pre-trained model.

When the self-supervised pre-training is successful:
- The pre-trained model provides latent representations that are relevant for a various set of downstream tasks
- If the downstream task lacks of labeled data to train a Deep Neural Network (DNN) from scratch, loading a pre-trained model is expected to improve the performance.
Our contributions
Considering all of the above, we propose a new method, named U-BARN (Unet-Bert spAtio-temporal Representation eNcoder).
We present two main contributions:
- A new spatio-temporal architecture to exploit the spatial, spectral and temporal dimensions of SITS. This architecture is able to handle irregular and unaligned annual time series.
- A self-supervised pre-training strategy suitable for SITS
Then, the quality of the representations is assessed on two different downstream tasks: crop and land cover segmentation. Due to the specific pre-training strategy, cloud masks are not required for the downstream tasks.

Method
U-BARN architecture
As described in the previous image, U-BARN is a spectro-spatio-temporal architecture that is composed of two successive blocks:
- Patch embedding : which is composed of a spatial-spectral encoder (a Unet) that processes independently each image of the SITS. No temporal features are extracted in this block.
- Temporal Transformer : which processes pixel-level time series of pseudo-spectral features. No further spatial features are extracted in this block.
The details of the U-BARN architecture are given in the full paper. We have used a Transformer to process the temporal dimension, as it enables to process irregular and unaligned time series while being highly parallelizable. Lastly, the latent representation provided U-BARN has the same temporal dimension as the input SITS.
Self-supervised pre-training strategy
Inspired by self-supervised learning techniques developed in natural language processing, we propose to train the model to reconstruct corrupted images from the time series. As shown in the next figure, during pre-training, a decoder is trained to rebuild corrupted inputs from the latent representation. The way images are corrupted is detailed on the full paper.

A reconstruction loss is solely computed on corrupted images. Additionally, to avoid training the model to reconstruct incorrect values, a validity mask is used in the loss. If the pixel has incorrect acquisition conditions, the pixel is not used in the loss. We want to emphasize that the validity mask is only used in the loss reconstruction. Therefore, the validity mask is not needed for the supervised downstream tasks. Lastly, an important pre-training parameter is the masking rate, i.e., the number of corrupted images in the time series. Increasing the number of corrupted image, complicate the pre-training task.
Experimental setup
Datasets
Three Sentinel 2 L2A datasets constituted of annual SITS are used:
- A large scale unlabeled dataset to pre-train U-BARN with the previously defined self-supervised learning strategy. This dataset contains data from 2016 to 2019 over 14 S2 tiles in France. The constructed unlabeled dataset is shared on zenodo : 10.5281/zenodo.7891924.
- Two labeled datasets are used to assess the quality of the pre-training. We perform crop (PASTIS) and land cover (MultiSenGE) segmentation.
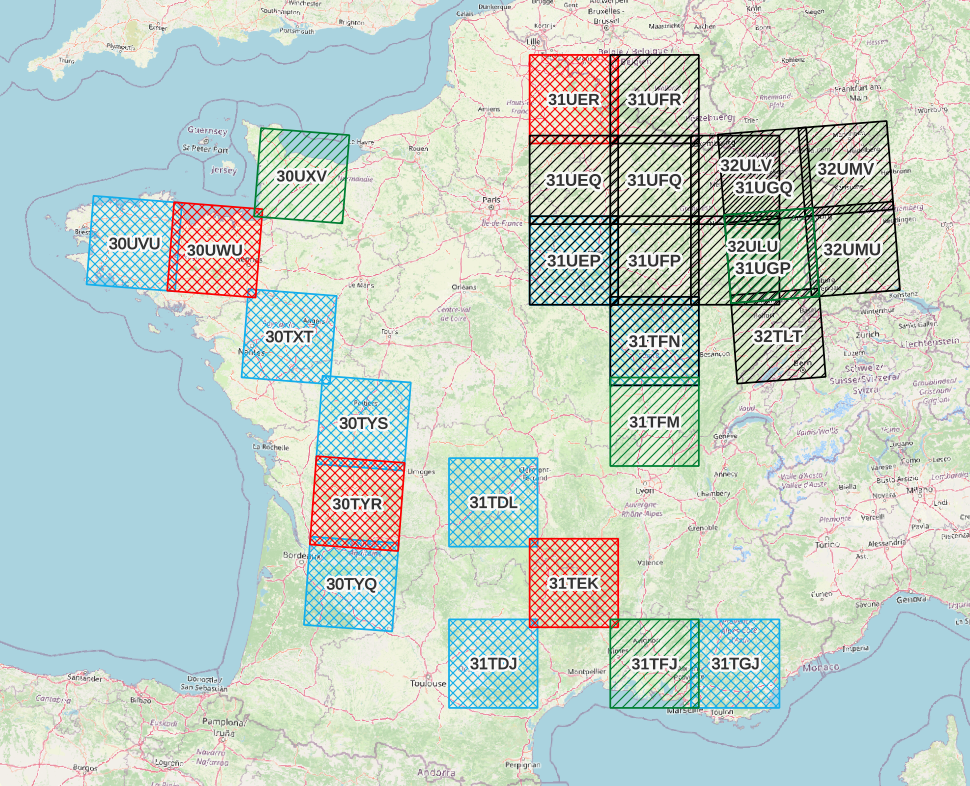
In all three datasets, the Sentinel 2 products are processed to L2A with MAJA. For these data-sets, only the four 10 m and the six 20 m resolution bands of S2 are used.
Experimental setup
The conducted experiments are summarized in the following illustration.
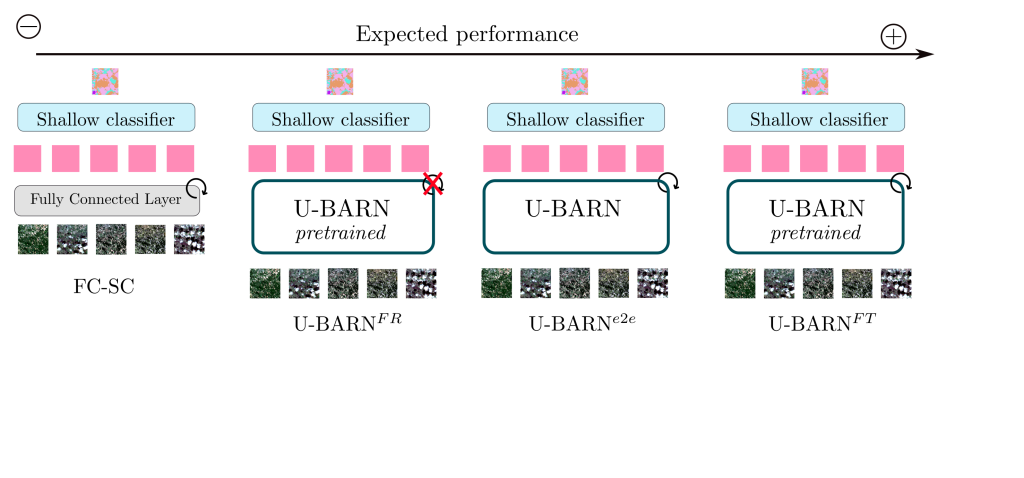
In the downstream tasks, the representations provided by U-BARN are fed to a shallow classifier to perform segmentation. The proposed shallow classifier architecture is able to process input with varying temporal sizes. We consider two possible ways to use the pre-trained U-BARN:
– Frozen U-BARN: U-BARNFR corresponds to the pre-trained U-BARN whose weights are frozen during the downstream tasks. In this configuration, the number of trainable parameters is greatly reduced during the downstream task.
– Fine-tuned U-BARN: U-BARNFT is the pre-trained U-BARN whose weights are the starting points for training the downstream tasks.
To evaluate the quality of the pre-training, we integrate two baselines:
– FC-SC: We feed the shallow classifier (SC) with features from a channel-wise fully connected (FC) layer. Although the FC layer is trained during the downstream task, if the U-BARN representations are meaningful, we expect U-BARNFR to outperform this configuration.
– U-BARNe2e: The fully supervised framework U-BARNe2e, where the model is trained from scratch on the downstream task (end-to-end (e2e)). When enough labelled data are provided, we expect U-BARNe2e to outperform U-BARNFR . The fully-supervised architecture is compared to another well known fully-supervised spectro-spatio-temporal architecture on SITS: U-TAE.
Results
Results of the two downstream segmentation tasks
| Model | Nber of trainable weights | F1 PASTIS | F1 MSENGE |
|---|---|---|---|
| FC-SC | 14547 | 0.509 | 0.323 |
| U-BARN-FR | 13843 | 0.618 | 0.356 |
| U-BARN-FT | 1122323 | 0.816 | 0.506 |
| U-BARN-e2e | 1122323 | 0.820 | 0.492 |
| U-TAE | 1086969 | 0.803 | 0.426 |
First, as expected, U-BARNFR outperforms FC-SC, showing that the features extracted by U-BARN are meaningful for both segmentation tasks. Second, we observe that in the MultiSenGE land cover segmentation task, the fine-tuned configuration (U-BARNFT) outperforms the fully-supervised one (U-BARNe2e). Nevertheless, when working on the full PASTIS labeled dataset, in contrast to MultiSENGE, we observe no gain from fine-tuning compared to the fully supervised framework on PASTIS. We assume that there may be enough labeled data for PASTIS task, to pre-train the model from scratch. Third, the results show that the newly proposed architecture is consistent with the existing baseline: the performance of the fully supervised U-BARN is slightly higher than that of U-TAE.
Labeled data scarcity simulation
We have conducted a second experiment where the number of labeled data is greatly reduced on PASTIS. As expected, with a decrease in the number of labeled data, the models’ performances drop. Nevertheless, the drop in performance is different for the pre-trained architecture U-BARNFT, and the two fully-supervised architectures U-BARNe2eand U-TAE. Indeed, we observe that when the number of labeled data is small, fine-tuning greatly improves the performance. This experiment highlights the benefit of self-supervised pre-training in configuration when labeled data is lacking.

Supplementary results
Investigation of the masking rate influence, training and inference time as well as detailed segmentation performances are available in the full paper.
Conclusion and perspectives
We have proposed a novel method for learning self-supervised representations of SITS. First, the proposed architecture’s performance is consistent with the U-TAE competitive architecture. Moreover, our results show that the pre-training strategy is efficient in extracting meaningful representations for crop as well as land cover segmentation tasks.
Nevertheless, the proposed method suffers from several limitations:
- The proposed architecture only processes annual SITS.
- The proposed architecture is less computationally efficient compared to the U-TAE, and further research should be done to reduce the number of operations in our architecture.
- The temporal dimension of the learned representation is the same as the input time series. In the case of irregularly sampled time series, the classifier in the downstream task must be able to handle this type of data.
Lastly, future work will focus on producing fixed-dimensional representations of irregular and unaligned SITS. Additionally, we intend to use other downstream tasks and integrate other modalities, such as Sentinel 1 SITS.
Acknowledgements
This work is supported by the DeepChange project under the grant agreement ANR-DeepChange CE23. We would like to thank CNES for the provision of its high performance computing (HPC) infrastructure to run the experiments presented in this paper and the associated help.

