
L’utilisation des données de télédétection au CESBIO
Plusieurs centres d’accès aux données sont en train d’être renouvelés au CNES, à l’ESA, et il manque souvent dans les premières versions des caractéristiques dont nous aurions besoin. Avec des collègues du CESBIO, nous avons fait une présentation au CNES de la manière dont nous utilisons les données. Voici une version écrite de cette présentation.
Bien évidemment, il y a autant de manière d’utiliser les données qu’il y a d’utilisateurs, mais nous pouvons cependant trouver quelques motifs récurrents chez tous les utilisateurs du CESBIO.
Et vous, comment utilisez vous vos données ? N’hésitez pas à préciser dans les commentaires de l’article. Il y a certainement d’autres modes d’utilisation que les nôtres, tout aussi efficaces.
Quels utilisateurs ?

Au CESBIO ou chez nos proches collègues, nous avons différents types d’utilisateurs :
- Des scientifiques compétents en informatique, capables de développer leurs applications et de gérer le passage à l’échelle de ces traitements sur de grands territoires
- Des scientifiques non spécialistes de codage, mais capables d’écrire des scripts, qui s’intéressent uniquement à une ou plusieurs AOI, éventuellement sur plusieurs années et avec plusieurs capteurs, qu ont besoin d’aide pour le passage à l’échelle
- Des scientifiques peu à l’aise avec le codage, ou qui n’en ont plus le temps (vous m’avez reconnu ?), et qui préfèrent des outils où l’on utilise des lignes de commandes déjà toute prêtes, voire même où l’on clique.
Finalement, nous travaillons rarement comme le montre l’illustration en entête de cet article, et quelques uns d’entre nous sont fiers d’affirmer ne jamais regarder les images (mais je sais qu’il mentent).
Quelles données ?
Au CESBIO, nous observons la végétation par satellite, nous avons donc besoin d’une assez haute résolution pour accéder aux parcelles agricoles, mais nous nous intéressons aussi à de larges territoires, et à leur évolution. Les données Copernicus, et notamment Sentinel-1 et -2, et plus tard Trishna, LSTM, ROSE-L ou CHIME nous seront très utiles. Il s’agit de données globales, avec une forte revisite, une bonne résolution. Elles sont donc très volumineuses, et distribuées par granules couvrant des territoires assez réduits.
Certains d’entre nous utilisent des observations globales, comme SMOS, VIIRS, Sentinel-3, Grace, et si en général leur résolution est inférieure, la fréquence de revisite augmente, et le volume reste élevé.
Nous avons aussi besoin de données auxiliaires, comme des données météo (analyses, prévisions, composants atmosphériques), des données de terrain et de validation…
Comment utilisons nous ces données ?
- les données que nous utilisons ont souvent une couverture globale et une revisite fréquente. Nous n’utilisons quasiment jamais une seule image, nous traitons de grandes régions, et souvent des années entières.
- nous sommes chercheurs, nous tâtonnons, modifions et améliorons nos traitements qui ne marchent jamais du premier coup. Nous développons nos outils de traitement, et les données sont donc traitées à de nombreuses reprises, jusqu’à ce que nous soyons satisfaits des résultats.
- il nous arrive de mettre au point des chaines de traitement intéressantes (si, si ), et nous avons dans ce cas besoin de tester le passage à l’échelle de ces traitements pour traiter des zones géographiques un peu plus étendues.
- les méthodes d’apprentissage automatique nécessitent souvent l’utilisation de vignettes réparties aléatoirement dans des paysages différents. Dans la phase d’apprentissage, nous n’avons pas besoin d’utiliser des images entières
- les données spatiales sont aussi utilisées à des fins pédagogiques, dans les cours et travaux dirigés de nos collègues enseignants chercheurs, ou à des fins de démonstration, pour mettre en évidence le potentiel d’applications des satellites, par exemple sur ce blog
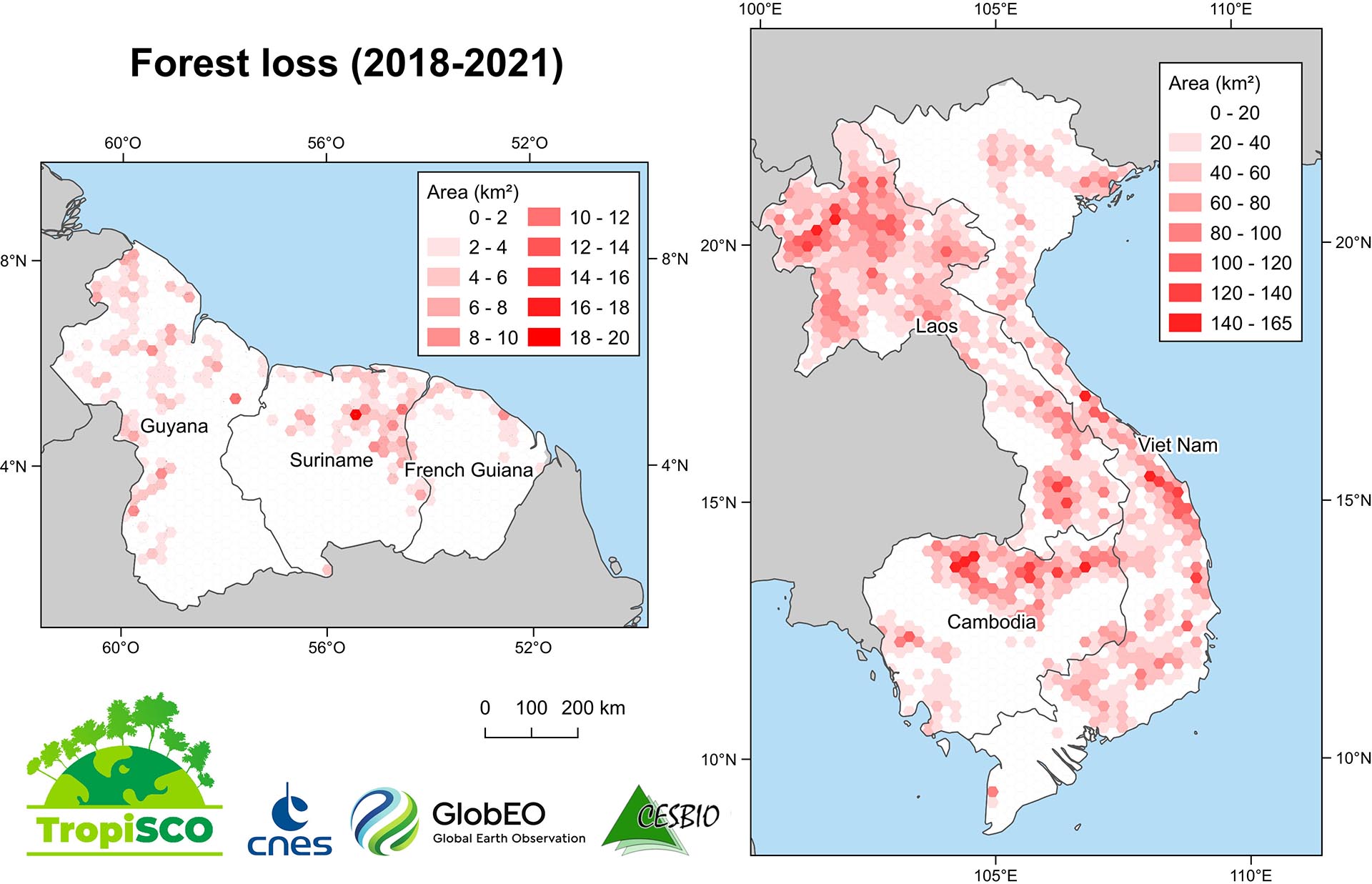
Téléchargement des données
Certes, la mode est au traitement proche de la donnée, sur des serveurs à distance (le Cloud), mais le téléchargement reste souvent nécessaire, quand par exemple les ressources de calcul à proximité des données sont limitées, ou payantes et onéreuses.
Vues les quantités de données que nous utilisons, il n’est absolument pas envisageable de télécharger les données en cliquant. Nous utilisons donc très peu les interfaces interactives de recherche des données, elles ne nous sont utiles que pour la découverte des données. Certains centres de distribution fournissent des API (Rest, STAC), qui conviennent à certains utilisateurs, mais elles nécessitent de dépenser du temps à comprendre ces interfaces, à les coder et les maintenir, car les interfaces changent. Fournir des outils de téléchargement validés, utilisables en lignes de commandes, est donc très important, et souvent oublié par les fournisseurs de données. Nous avons par exemple fourni des outils de téléchargement (Peps_download, Theia_download, Sentinel_download, Landsat_download), mais nous avions largement sous-estimé la charge de documentation, maintenance et de réponse aux questions, ces outils ayant rencontré du succès. A notre avis, c’est aux centres de diffusion de les fournir, ce n’est pas le rôle des utilisateurs.

Les apprentissages automatiques sont souvent réalisés à partir de vignettes de petite taille sélectionnées aléatoirement dans les produits. pour économiser du temps de transfert, il serait donc utile que les outils de téléchargement permettent de sélectionner la zone d’intérêt, les dates et les bandes spectrales. Pour celà, le stockage des données en un format optimisé pour le web, comme le Cloud Optimised Geotiff (COG), serait bien utile.
Certains d’entre nous ont besoin de croiser des bases de données, par exemple pour repérer des acquisitions simultanées entre différents satellites, souvent sur des serveurs différents, en prenant en compte par exemple la couverture nuageuse ou les angles de prise de vue. Une API ouvrant l’accès à ces informations lors de requêtes à la base de données est donc très utile, avec le moins de limitations possibles en termes de performances et de nombres d’accès.
Traitement à la demande
De la même manière que pour les téléchargements, certains sites proposent de lancer des traitements à la demande. Par exemple, lancer une correction atmosphérique, ou un outil de super-résolution. La encore, si nous les utilisons, ce ne sera pas pour les faire tourner sur une seule image, mais pour traiter de grandes quantités de données. Nous avons donc besoin d’accéder à ces traitements en ligne de commande ou en lançant des scripts sur le serveur où se trouvent les données.
Calcul proche des données
Traiter les données sur le cloud permet d’économiser le temps de téléchargement, les données en sortie des traitements étant souvent moins volumineuses que celles en entrée (par exemple, une carte d’occupation des sols produite à partir d’une année de données Sentinel-2). Cela présente cependant de nombreuses difficultés, et nous aimerions que l’on nous facilite la tâche.
D’un cloud à l’autre, les outils pour automatiser les traitements, ouvrir des machines virtuelles, lancer des processus peuvent différer. Si les données dont nous avons besoin sont sur des clouds différents, ou si nous souhaitons pouvoir déplacer nos traitements d’un cloud à l’autre, nous avons besoin d’apprendre les protocoles API propres à ces clouds, et de les adapter quand nous en changeons. Ce n’est pas efficace.
Nos travaux commencent presque toujours par la constitution de cubes de données, dont les dimensions sont les coordonnées spatiales, le temps, les bandes spectrales ou des informations diverses. Le format actuel des données Sentinel-2 peut être vu comme un cube de données, avec une granularité par date. Cependant, il peut-être pratique de réaliser des cubes de données plus grands ou plus petits que les tuiles de 110 x 110 km² de données. L’utilisation d’une API qui génère ces cubes de données à la volée, et permet de leur appliquer des traitements est donc très intéressante. C’est le cas de la librairie OpenEO. Ce n’est pas la seule API de ce genre, mais elle est bien faite et a le bon gout d’être un logiciel libre.
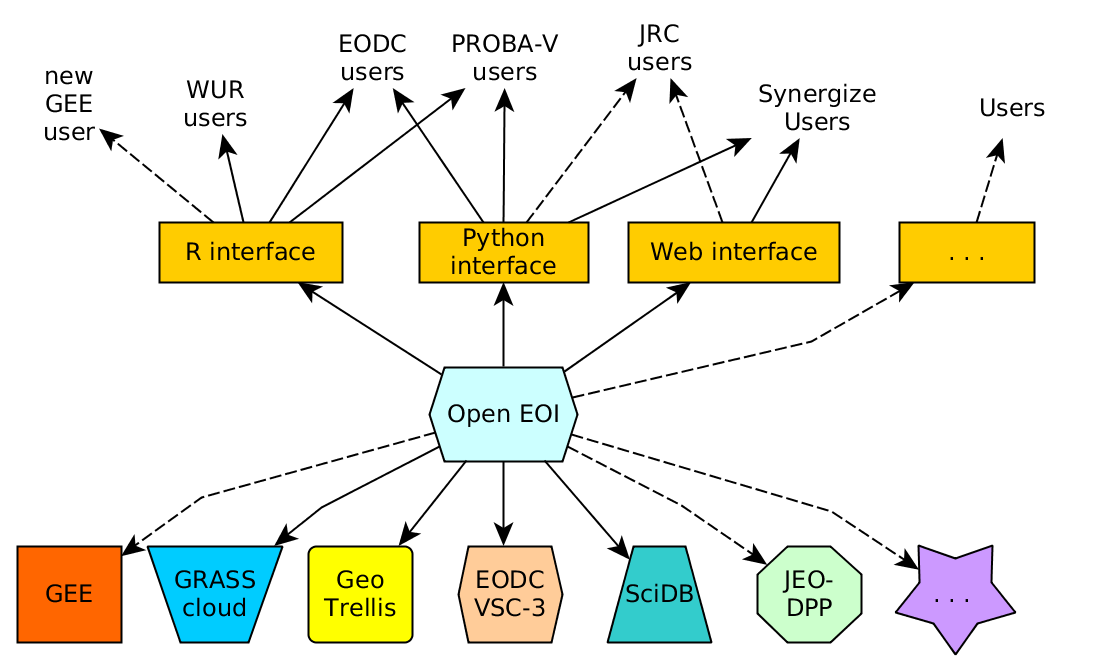
Pour pouvoir utiliser des données réparties sur plusieurs clouds, OpenEO doit être installée côté serveur sur ces clouds. OpenEO utilise donc la notion de fédération de données. La génération des datacubes peut-être réalisée en parallèle sur plusieurs clouds, chaque cloud préparant la partie du datacube dont il possède les données. Pour un centre de distribution de données, participer à cette fédération donne donc aussi de la visibilité qu’il met à disposition.
Nous avons quelque peu insisté auprès du CNES pour que ce soit mis en place, et le CNES a intégré cette demande a sa feuille de route et a lancé une étude du type « preuve de concept » 🙂 .
De l’aide… de l’aide…
Trouver de l’information sur toutes ces solutions demande beaucoup de recherches, mais ne devrait pas être l’objet principal des recherches des chercheurs. Nous avons donc vraiment besoin d’information, d’exemples, d’annonces permettant d’anticiper les changements et améliorations. Tout cela est couteux et n’est pas toujours inclus dans les priorités.
Nos collègues qui préparent le serveur Géodes au CNES semblent avoir bien pris en compte nos besoins, et nous préparent un portail d’accès, un site d’informations et support, des outils de téléchargement et travaillent à l’implémentation d’Open EO. Celà prend du temps bien sûr, mais devrait permettre un réel par rapport aux versions encore en activité comme PEPS.
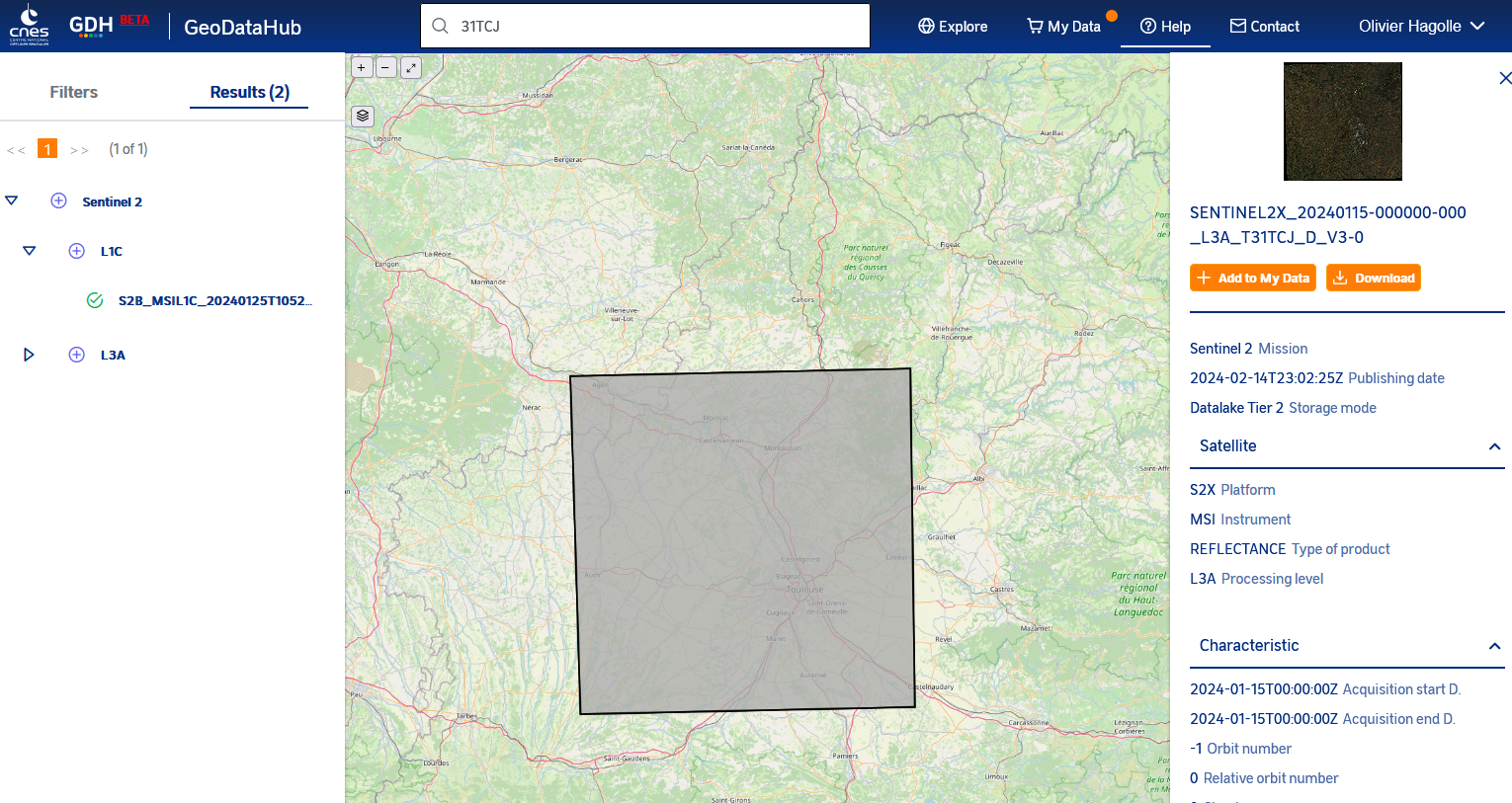

Version Beta de l’interface et du portail de Geodes, qui seront disponibles dans quelques semaines.
Remerciements
Cet article est le résultat de nombreuses discussions au CESBIO, avec des contributions directes de Sylvain Ferrant, Julien Michel, Emmanuelle Sarrazin et Jordi Inglada. Merci à tous !
