Several issues found in recent papers on cloud detection published in MDPI remote sensing
In the last few months, several papers on Sentinel-2 cloud detection have been published by MDPI remote sensing journal. We found large errors or shortcomings on two of these papers, that should not have been allowed by the reviewers or editors. The third one is much better, even if we disagree with one of its conclusions.
Introduction
Before analyzing the papers, let’s review a few points that someone interested in the performances of Sentinel-2 cloud masks should know.
1- False cloud negatives (cloud omissions) are worse than false cloud positives:
- given that Sentinel-2 observes the same pixel every fifth day, false cloud positives only reduce the number of available data for the processing, but one can expect the same pixel will be available and clear -and classified as such- 5 or 10 days before or after. Of course, systematic false positives, like, for instance, the classification of bright pixels as clouds, should be avoided as they would mean such a pixel would never be available during the long period in which it is bright;
- false cloud negatives can degrade the analysis of a whole time series of surface reflectance, yielding a wrong estimate of bio-physical variables or of land cover classification for instance.

2 – Cloud masks should be dilated, for at least three reasons:
- all Sentinel-2 spectral bands do not observe the surface in the exact same direction. As the cloud mask is made using a limited number of bands, it is necessary to add a buffer around it so that the clouds are asked in all the bands;

- cloud edges are often fuzzy, and the pixels in the cloud neighborhood can be affected by the limbos of the cloud;
- clouds scatter light around them, and the measurement of surface reflectances is disturbed by this effect, named « adjacency effect » in remote sensing jargon.
For these reasons, in our software MAJA, we recommend to use a parameter which dilates the cloud mask by 240 meters. This dilation is a parameter, and different cloud masks should be compared using the same value of this parameter. Dilating the cloud mask will lower the false negatives, and increase the false positives, and overall, it will reduce the noise due to clouds in time series of surface reflectance.
3- Cloud shadows or clouds are both invalid pixels:
- clouds and cloud shadows disturb surface reflectance time series. These pixels are therefore invalid for most analyses. we do not know of any user who really needs to know if an invalid pixel is in fact a shadow or a cloud. And moreover, a pixel can very often be both a cloud and a shadow, as some clouds partly cover their shadows. It is therefore not very useful to separate both classes in the validation, as it can bring differences if the hypotheses are different between the reference and the cloud detection method.
We have followed these guidelines in our own cloud mask validation paper, also published in remote sensing, and provided more details about their justification. This being said, we can now analyze the three papers.
Sanchez et al: Comparison of Cloud cover detection algorithms on sentinel–2 images of the amazon tropical forest

This paper compares the quality of FMask, Sen2cor and MAJA cloud masks over the Amazon forest, which has an excessively high cloud cover. Such a cloud cover is not favorable to MAJA, which is a multitemporal method that works better when the surface is seen cloud free once per month. We are therefore not surprised that MAJA is not at its best in this comparison. The paper relies on a careful elaboration of reference fully classified images. It is a serious work, but which still includes at least 4 shortcomings concerning MAJA’s evaluation:
- MAJA cloud mask was improperly decoded, and the authors wrongly concluded that MAJA could not detect cloud shadows. This error has been admitted by the authors. The Joined image shows that, for the images used by Sanchez et al, the cloud shadows are indeed detected.

We asked MDPI for a correction, but while it seems that MDPI tries to be fast in the review process, it is not as fast to recognize errors and publish corrections. We signaled the errors in September, asking how to correct it. We received an answer end of October, submitted our comment in November, which was finally published in March, after a minor revision in January which requested us to change only one single word. With our comment, MDPI also published an answer from the authors, who acknowledge the error on the decoding, but did not bother to show the results after separating the results obtained with a revisit of 20 days, and those with a revisit of five days. MDPI did not insist, which we found -to say the least- disappointing. Meanwhile, this paper with false results has been quoted 9 times.
EDIT : as this blog post has had some success, I have received some feedback, and one of the actual reviewers of the paper told me he had submitted comments close to ours, and these comments where disregarded by the authors and the paper was accepted by MDPI, while the reviewer still recommended Major revisions.
Zekoll et al: Comparison of Masking Algorithms for Sentinel-2 Imagery

This paper compares three cloud detection codes, FMask, ATCOR and Sen2cor, by comparing the cloud masks generated by the automatic methods to reference data taken manually:
« Classification results are compared to the assessment of an expert human interpreter using at least 50 polygons per class randomly selected for each image ».
The method by Sanchez et al used fully classified images, and so did our method, but the one used in Zekoll et al is based on selected polygons, which might be less accurate, because it is highly dependent on the choice of the samples. For instance, with such a method, you tend not to select samples near the cloud edges, because it is hard to do so manually. But the issue is that the cloud edges are one of the most difficult cases, while the center of a cloud is usually easier to classify automatically. Cloud edges are also one of the cases where Sen2cor classification is often wrong, avoiding to sample them is a convenient way to obtain good results. The paper does not show any example of reference classification, which is described in one sentence and a graph, so the reader can just hope that the work was done properly.
The paper contains also a sentence that should have shocked a good reviewer:
« However, dilation of Sen2Cor cloud mask is not recommended with the used processor version because it is a known issue that it misclassifies many bright objects as clouds in urban area, which leads to commission of clouds and even more if dilation is applied. »
It could be translated by, « let’s avoid the dilation or it would reveal the real value of Sen2cor ». How can a review accept such a statement ? Yes, the disclaimer is present in the paper, but the performance quoted in the abstract and conclusion does not take it into account. It is therefore misleading.
And finally, the most beautiful construction in the paper is in the abstract:
« The most important part of the comparison is done for the difference area of the three classifications considered. This is the part of the classification images where the results of Fmask, ATCOR and Sen2Cor disagree. Results on difference area have the advantage to show more clearly the strengths and weaknesses of a classification than results on the complete image. The overall accuracy of Fmask, ATCOR, and Sen2Cor for difference areas of the selected scenes is 45%, 56%, and 62%, respectively. User and producer accuracies are strongly class and scene-dependent, typically varying between 30% and 90%. Comparison of the difference area is complemented by looking for the results in the area where all three classifications give the same result. Overall accuracy for that “same area” is 97% resulting in the complete classification in overall accuracy of 89%, 91% and 92% for Fmask, ATCOR and Sen2Cor respectively. »
Instead of giving in the abstract the Overall Accuracy for all reference data sets, which is not good (despite using non dilated reference cloud masks), the authors have found a way to show the fast reader that the « overall accuracy is 92% for Sen2cor ». You need to carefully read between the lines to understand that it is only for the pixels on which the three methods agree, ie. for the pixels which are easy to classify. The real performance for cloud detection is available but lost in the results :
Fmask performs best for the classification of cloud pixels (84.5%), while ATCOR and Sen2Cor have a recognition rate of 62.7% and 65.7%, respectively
The corresponding User Accuracy of FMask is low, but most of the Cloud commision errors are due to the dilation.
To conlude, here is one element which explains the low quality of the paper :
Received: 1 December 2020 / Revised: 25 December 2020 / Accepted: 27 December 2020 / Published: 4 January 2021
Congratulations to the MDPI review process, who accepted this paper in less than one month, in a period that includes the Christmas and New Year break . Let me recall that our negotiation with MDPI for adding a comment to Sanchez et al took seven months.
I have to add that I just saw a presentation at the S2 Validation Team meeting from by the first author, V. Zekoll, a PhD student. The presentation was much better than the paper, and which only focused on the comparison of the three methods she studied, and did not even show any comparison with the reference. This blog post does not aim at blaming her, but rather the editing process.
Cilli et al: Machine Learning for Cloud Detection of Globally Distributed Sentinel-2 Images
The last paper by Cilli et al avoids most of the traps in which the other papers fell. It takes the necessary dilation into account, even though the reference mask was not dilated. The reference validation data set was a good one based on fully classified images. In fact it was the data set we generated three years ago and made available to the public. We are happy it was useful and well used. But finally, the paper missed the necessity to detect cloud shadows, i just suppose it is a work in progress.
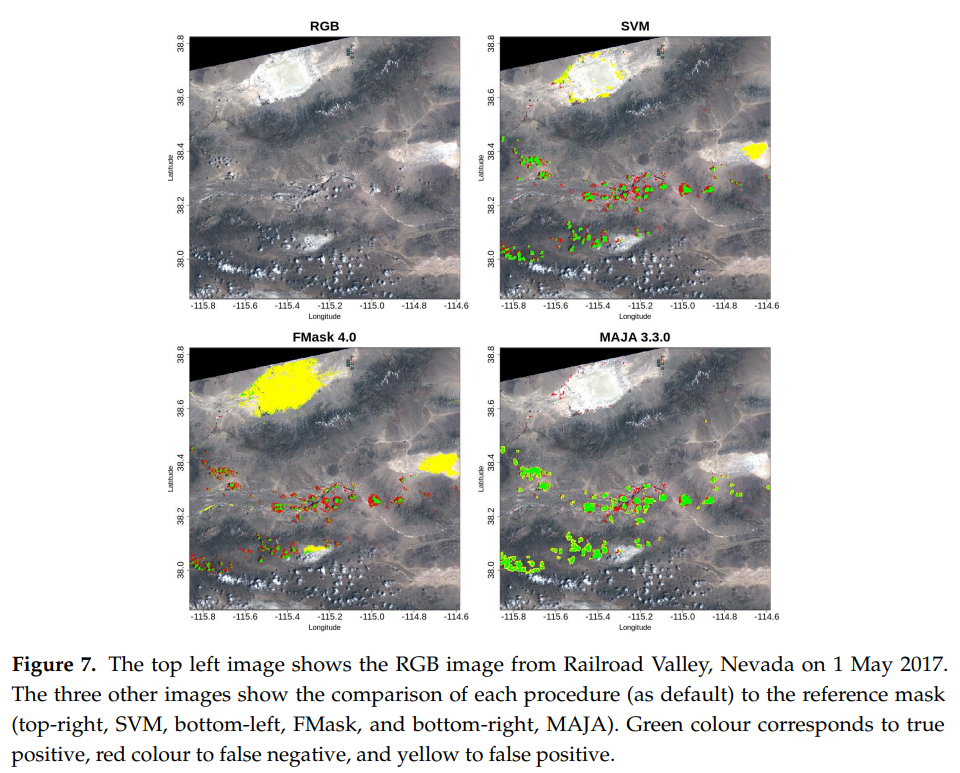
The paper compares machine learning approaches and more classical threshold based methods including MAJA, Sen2cor and FMask. The machine learning method uses a database by Hollstein et al as training data set, and evaluates all methods against CESBIO’s data set.
The conclusions correspond to how we designed MAJA. MAJA is the most sensitive, but has some false positive clouds, which mostly correspond to the dilation in the products generated by MAJA. The authors also note that MAJA does not have false positives on bright pixels, while the other methods have.
The conclusion of the paper for the threshold based method is as follows :
« In general, MAJA resulted in the most sensitive (95.3%) method and FMask resulted in the most precise (98.0%) and specific (99.5%); however, it is worth noting that according to specificity the difference with Sen2Cor is negligible (99.4%). »
The SVM method developed by Cilli et al is less sensitive than MAJA but more precise (probably as the dilation is thinner).
However, I am puzzled by the following sentence:
« These findings should be taken into consideration as the main purpose of cloud detection is avoiding false positives, especially for change detection or land cover applications. »
I had an email interaction with some of the authors, who come from the machine learning domain and are rather new to remote sensing, and they recognize that as Sentinel-2 provides time series, it is more relevant to avoid false negatives than false positives. The authors concede that they did not take into consideration that Sentinel-2 data are not single images, but time series of images. This is again a questionnable position that passed through the MDPI review process.
Conclusion
Validating cloud masks it not as easy as it seems. It includes numerous pitfalls, and requires both a good understanding of cloud mask processors strategies and tuning, and a robust methodology. Falling into one of these traps is not shocking in itself and can fuel scientific discussions. But the fact that the cited articles go into publication with such shortcomings despite the usual revision process is surprising. This questions both the very fast review process of MDPI and the multiplication of guest editors who may not be specialists.
To finish, I have to say that I have published several papers in MDPI, and I appreciated that the review process wasquick and the reviews not too severe, my critics can apply to my own papers. Moreover, I have been a guest editor for 4 special issues of MDPI over the years :
- SPOT (Take5) special issue
- VENµS special issue
- Sentinel Analysis Ready Data
- Sentinel-2 science and applications
My feedback in these special issues, is the easyness to open one, but also the pressure from MDPI to have a fast processing. This pressure results in only one member of the guest editing board handling all the papers, because it takes a long time to coordinate on who will be handling the paper. For the SPOT(Take5) paper, I handled most papers, except those of which I was a co-author. For the other special issues, the main guest editors does most of the work, except for the few papers that fall exactly in my field of expertise.
Written by O.Hagolle and J.Colin