Everything, Everywhere, All at Once
This blog post is not a review of the excellent and deeply philosophical, parallel-universes delirium movie by Daniel Kwan and Daniel Scheinert, but the title of this drama resonates with the capabilities of our latest algorithm, which has just been published in Remote Sensing of Environment:
J. Michel and J. Inglada, « Temporal attention multi-resolution fusion of satellite image time-series, applied to Landsat-8/9 and Sentinel-2: all bands, any time, at best spatial resolution, Remote Sensing of Environment », Volume 334, 2026, 115159, ISSN 0034-4257, https://doi.org/10.1016/j.rse.2025.115159
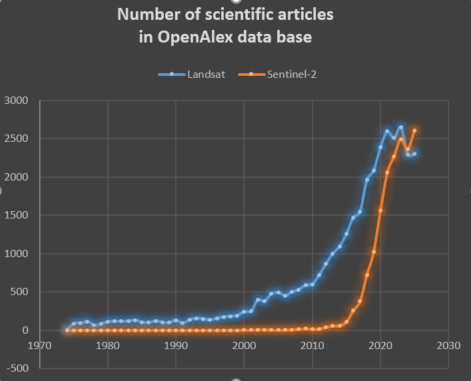
While Single Image Super-Resolution is intensively studied in the literature (Google scholar returns 39 600 matches for year 2025), it is not the most adapted choice when dealing with several Satellite Image Time Series (SITS) from multiple global coverage satellite missions with different trade-offs between spatial resolution and revisit period. In this situation, at every location and for every coarser spatial resolution images, regular finer spatial resolution observations exist, albeit probably not in the exact same spectral bands.
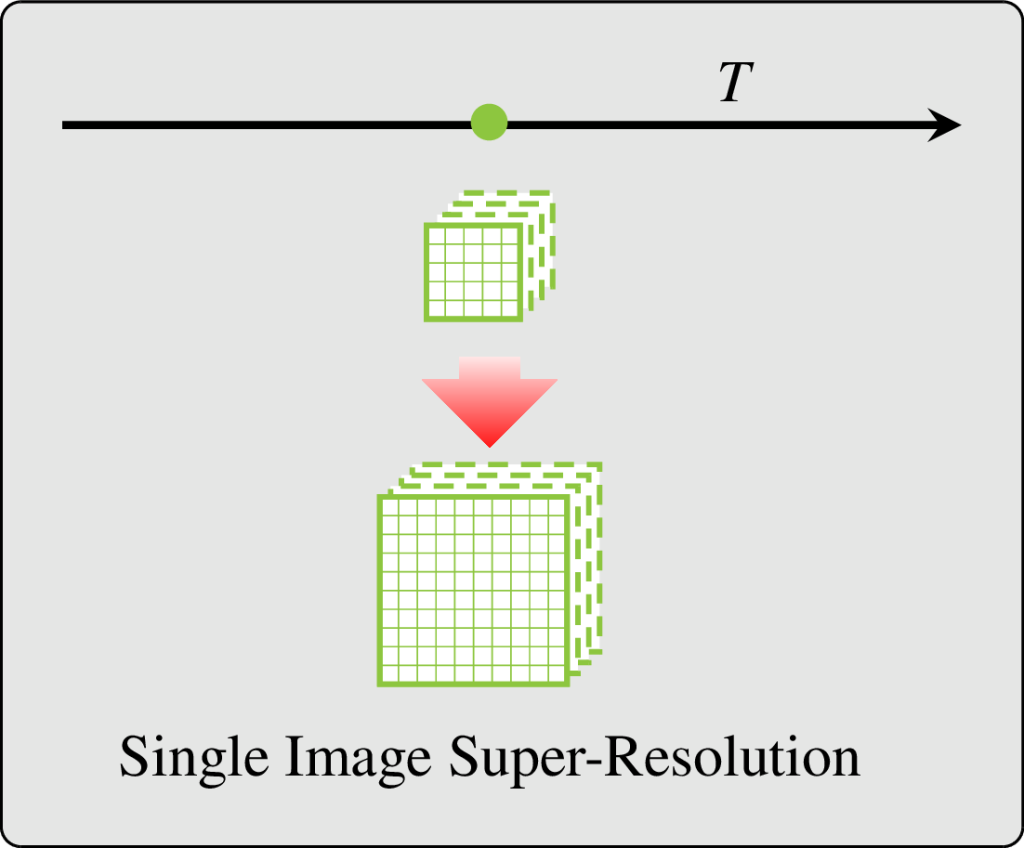
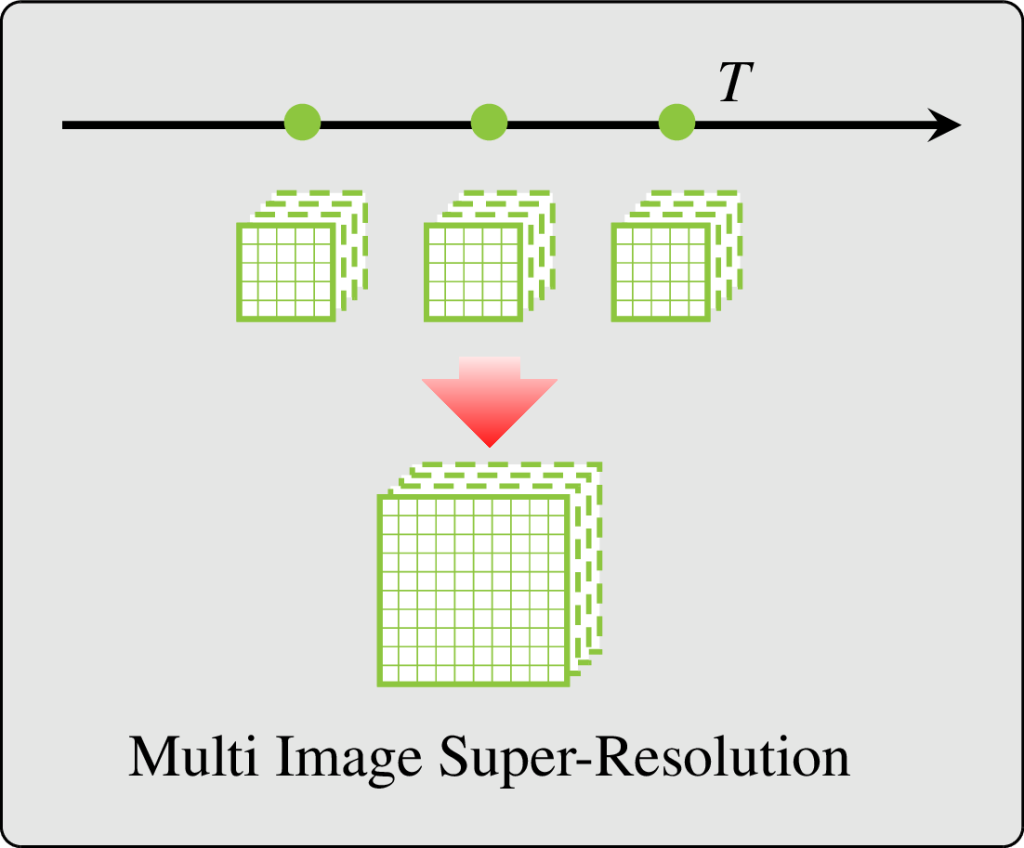
The literature addresses this situation with band-sharpening (sharpening a low resolution image with a concomitant high resolution image of different spectral bands) and spatio-temporal fusion (sharpen low resolution image using pairs of low and high resolution images observed at different times). However, each family of methods has its own limitations: they require synchronous acquisitions, spatio-temporal fusion mostly ignores the acquisition time in the processing (and thus it does not matter how old are the supporting pairs of data), and often require scale invariance and cloud free images for training.
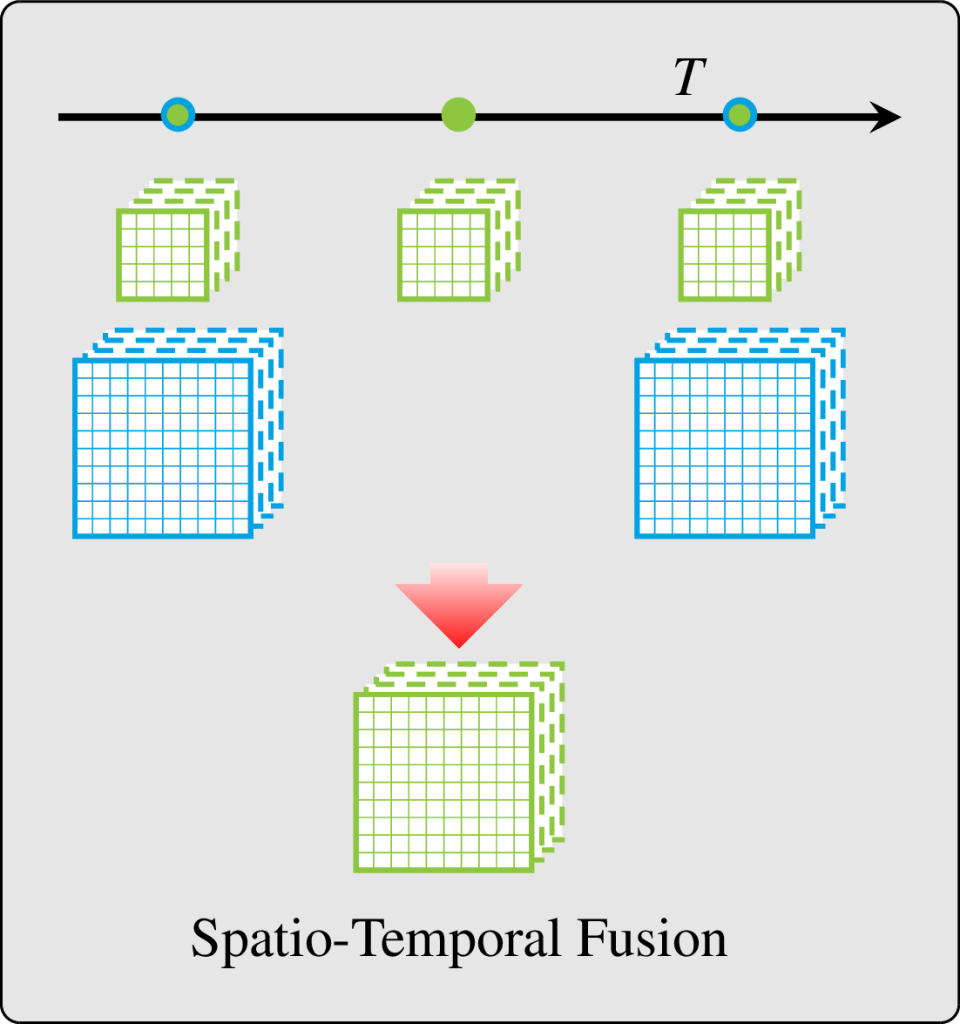
In our last paper, we hypothesize that a more complete formulation of the problem would allow to avoid unrealistic assumptions required by those methods. We reframed the fusion problem as the ubiquitous task: predicting all the spectral bands, from all the input sensors, at the finest spatial resolution, and at any acquisition time requested by the user.
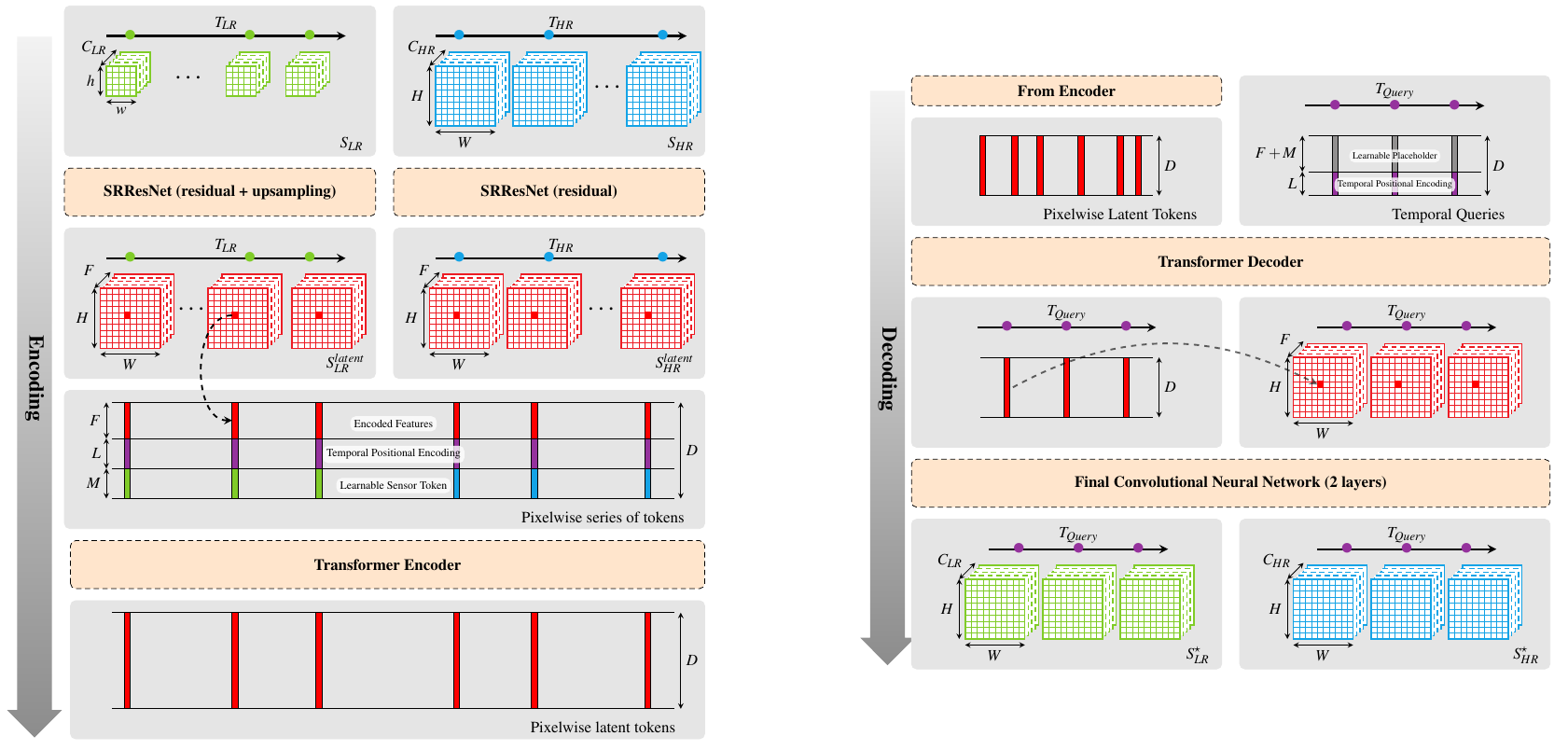
We proposed a new method termed TAMRF (French pronunciation at your own risk) for Temporal Attention, Multi-Resolution Fusion of SITS. TAMRF is an Auto-Encoder Deep-Learning model combining two instances of SRResNet, a well-known residual CNN-based architecture for Single Image Super-Resolution (one for each source) in the spatial and spectral dimension, with a transformer handling the fusion of the sensors and the temporal extrapolation. Along with this architecture, we also proposed a sensor and temporal Masked-Auto-Encoding strategy, where the model learns to reconstruct data that have been masked from its input, and original learning biases (loss terms) to favour high resolution details in the prediction and avoid cloud leakage (it is noteworthy that the model does see cloud masks in its inputs).
Does TAMRF solve the ubiquitious task? The answer is yes! Suppose that we input the model with one year of Sentinel-2 and Landsat data, as follows (this is actually an extract from our LS2S2 dataset that has been published along with the paper):

Whenever a Landsat date is observed, the model outputs all its spectral bands, but at 10-meter spatial resolution (see below):
However, if we observed Landsat, TAMRF can predict all spectral bands from Sentinel-2 at 10-meter spatial resolution at the same date, including the Red-Edge bands that are missing on Landsat and have only 20-meter spatial resolution on Sentinel-2:
Of course, if we observed Sentinel-2, we can predict all its spectral bands at 10-meter spatial resolution:
But what if Sentinel-2 was observed, but the image is partly cloudy? No problem, TAMRF will make a prediction of the surface reflectance beneath the clouds, and will also predict Landsat spectral bands, all at 10-meter spatial resolution:

Finally, TAMRF can also predict dates that were not observed by neither Sentinel-2 nor Landsat:

TAMRF is also very flexible in terms of input, and can accept any number of Sentinel-2 and Landsat dates! It can even process Landsat only or Sentinel-2 only, and still make high quality predictions. Though there is no other model with such flexibility and versatility in the literature, we compared TAMRF with other recent models on subtasks, including Gap-Filling of Sentinel-2, Band-Sharpening of Sentinel-2, Spatio-Temporal Fusion and Thermal Sharpening of Landsat. In all those experiments, a single pre-trained TAMRF model has been used. The article shows that TAMRF is on par or better than ad-hoc models in terms of performances! Finally, it can be noted that TAMRF is still a reasonably small model, with only 1.4M of parameters to achieve this level of flexibility.
So, what’s next ? Well, in terms of application TAMRF already provides high quality predictions and is ready to be tested by users that want to produce maps of their favourite essential variable from 10-meter spatial resolution cloudless time-series estimated from Landsat and Sentinel-2. TAMRF could also revisit or replace the Level 3 monthly synthesis product, since it can make a monthly prediction at high spatial resolution, free of clouds (and free of interpolation artifacts from cloud masks), jointly estimated from two sensors! This is illustrated in the following figure:

On the methodological side, we are planning to modify the architecture in order to get rid of the sensor-specific SRResNet in order to aim for a sensor-agnostic fusion model. It would also be very interesting to include support for Medium Resolution data such as Modis or Sentinel-3, or later TRISHNA and LSTM, which would further help to make good predictions in large temporal gaps. A final important perspective is to also predict uncertainties in order to inform the user of the quality of the prediction, especially in long temporal gaps caused by persistent cloud coverage.